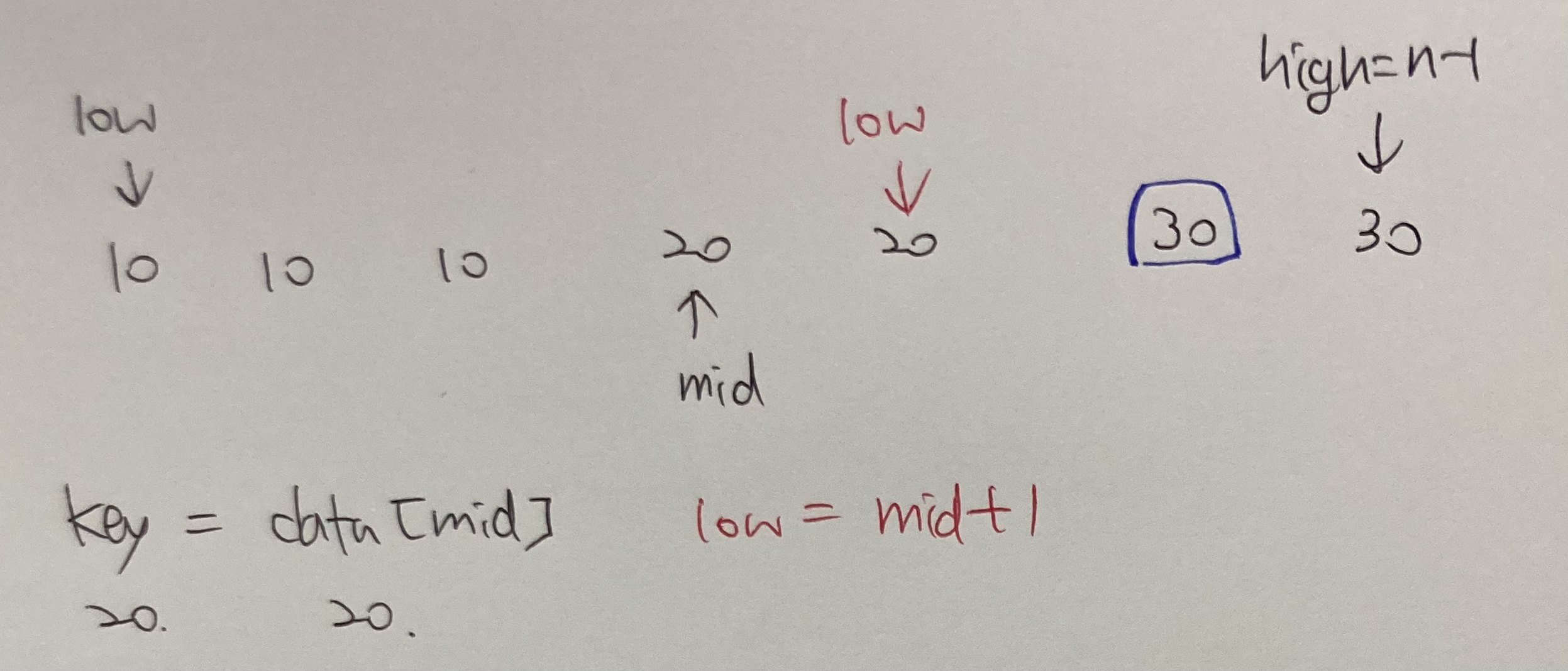intcompare(constvoid* a, constvoid* b) { if (*(int*)a > *(int*)b) return1; elseif (*(int*)a < *(int*)b) return-1; return0; }
intlower_bound(int data[], int n, int key) { int low, high, mid;
low = 0; high = n-1;
while (low < high) { mid = (low+high) / 2; if (key <= data[mid]) high = mid; else low = mid + 1; }
return high; }
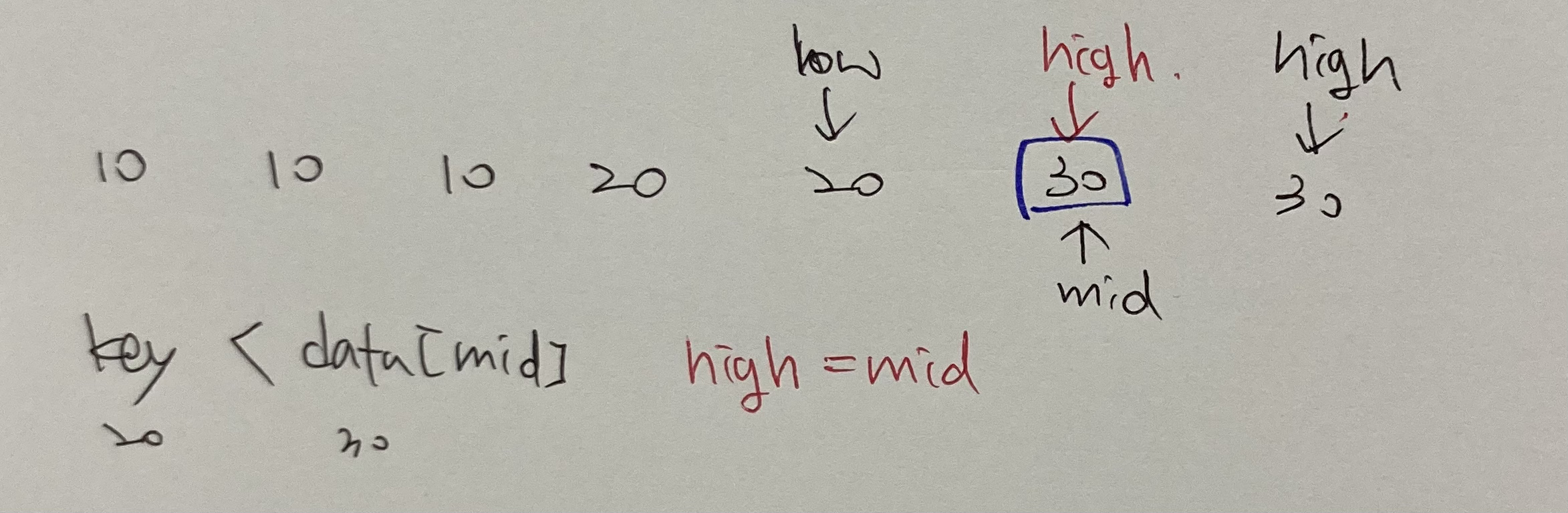
intupper_bound(int data[], int n, int key) { int low, high, mid;
low = 0; high = n-1;
while (low < high) { mid = (low+high) / 2; if (key < data[mid]) high = mid; else low = mid + 1; }
if (data[high] == key) return high + 1;
return high; }
intmain() { scanf("%d", &n); int arr[n]; for (int i = 0; i < n; i++) scanf("%d ", &arr[i]);
qsort(arr, n, sizeof(int), compare);
scanf("%d", &m); int brr[m];
for (int i = 0; i < m; i++) scanf("%d ", &brr[i]); // lower_bound, upper_bound int lower, upper; for (int i = 0; i < m; i++) { lower = lower_bound(arr, n, brr[i]); upper = upper_bound(arr, n, brr[i]); printf("%d ", upper-lower); } }
이 문제를 풀기 위해서 upper_bound 함수에서 아래 조건을 추가해줘야한다.
1 2
if (data[high] == key) return high + 1;
왜냐하면.. upper_bound 함수의 반환 값은 key 값을 초과하는 첫 번째 값의 인덱스인데 key가 정렬에서 가장 큰 수라면 반환 값이 존재하지 않기 떄문이다. 그래서 n-1을 반환한다. 이 문제는 key의 개수를 알아내는 것이 목표이기 때문에 해당 경우에만 +1을 해줘야 한다.